
Regardless of what problem you are solving, an interpretable model will always be preferred because both the end-user and your boss/co-workers can understand what your model is doing. Model Interpretability also helps you debug your model by giving you a chance to see what the model thinks is essential.
Furthermore, you can use interpretable models to combat the common belief that Machine Learning algorithms are black boxes and that we humans aren't capable of gaining any insights into how they work.
This article is the first in my series of articles to explain the different methods of achieving explainable machine learning/artificial intelligence.
Plan for this series
My series of articles will cover both theoretical and practical information about making machine learning explainable. The articles are structured in the following way:
Part 1: Machine Learning Model Interpretability (this article)
- What is Model Interpretation?
- Importance of Model Interpretation
- What features are important for the model?
- Understanding individual predictions
Part 2: What features are important
- How to get Feature importance for different types of models
- What are Partial Dependence plots, and how can they be used
Part 3: Interpreting individual predictions
- Local Interpretable Model-Agnostic Explanations (LIME)
- SHapley Additive exPlanations (shap values)
Why is interpretability in machine learning important?
Even today, data science and machine learning applications are still perceived as black boxes capable of magically solving a task that couldn't be solved without it. However, this isn't at all true; then, for a data science project to succeed, the development team must understand the problem they are trying to solve and know what kind of model they need for the problem at hand.
However, considering that most business people won't have an intuitive understanding of the machine learning pipeline and therefore won't understand your fancy accuracy metrics or loss functions, you need another way to show them your model's performance.
Furthermore, good performance doesn't always mean that your model is doing the right thing, and therefore often, the following questions emerge:
- Why should I trust the model?
- How does the model make predictions?
Data scientists and researchers have been trying to answer these questions for several years now and have come up with multiple approaches to extract information about the decision process of machine learning models.
Some of these methods are model-specific, while others work for every model no matter the complexity. Speaking of complexity, every data scientist will know of the model interpretability vs. model performance trade-off, which says if we increase the complexity of the model, it will get harder to interpret it correctly.
Generally, linear models and tree-based models can be easily interpreted because of their intuitive way of getting to the predictions. Still, you might need to sacrifice accuracy since these models are simple and can easily under- or overfit depending on the problem.
On the other hand, you have more complex models like ensemble models (e.g., Random Forest, XGBoost, etc.) and deep neural networks, which are especially hard to interpret because of their complexity.
For real-world problems like fraud detection, self-driving cars, or loan lending, the model doesn't only need to perform well but also needs to be easily interpretable so we can see why a loan was/wasn't approved and use our domain expertise to validate or correct the decision.
Understanding Model Interpretation
As mentioned above, model interpretability tries to understand and explain the steps and decisions a machine learning model takes when making predictions. It gives us the ability to question the model's decision and learn about the following aspects.
- What features/attributes are important to the model? You should be able to extract information about what features are important and how features interact to create powerful information.
- Why did the model come to this conclusion? You should also have the ability to extract information about specific predictions to validate and justify why the model produced a certain result.
Types of Model Interpretability
Data scientists and researchers have developed a lot of different types of model interpretability technics over the years. These technics can be categorized into different types as described in the excellent free online book "Interpretable Machine Learning, A Guide for Making Black Box Models Explainable" by Christoph Molnar.
Intrinsic or post hoc? Intrinsic interpretability refers to models that are considered interpretable due to their simple structure, such as linear models or trees. Post hoc interpretability refers to interpreting a black box model like a neural network or ensemble model by applying model interpretability methods like feature importance, partial dependence, or LIME after training the model.
Model-specific or model-agnostic? Model-specific interpretation tools are specific to a single model or group of models. These tools depend heavily on the working and capabilities of a specific model. In contrast, model-agnostic tools can be used on any machine learning model, no matter how complicated. These agnostic methods usually work by analyzing feature input and output pairs.
Local or global? Does the interpretation method explain an individual prediction or the entire model behavior?
What features are important, and how do they affect the predictions
How does the model behave in general? What features drive predictions? Which features are not worth the money and time it takes to collect them? These are all important questions a company might ask when considering building a machine learning solution for some task. Global model interpretability helps answer these questions by explaining what features are important, how they are important, and how they interact together.
Feature Importance
The importance of a feature is the increase in the prediction error of the model after we permuted the feature’s values, which breaks the relationship between the feature and the true outcome. — Interpretable Machine Learning, A Guide for Making Black Box Models Explainable
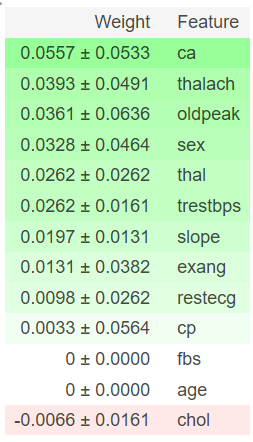
Feature importance is a straightforward concept that is implemented in most of the major machine learning libraries, including Scikit Learn, XGBoost, and LightGBM.
A feature is considered important if shuffling its values increases the model error significantly because that means that the model relies on that feature for the prediction. In contrast, a feature is unimportant if shuffling its values does not affect the model's error.
Partial Dependence Plots (PDP)
While feature importance shows us what features are important, it doesn't give us information on the effect of a particular change in the feature. A partial dependence plot can show whether the relationship between the target and a feature is linear, exponential or more complex.
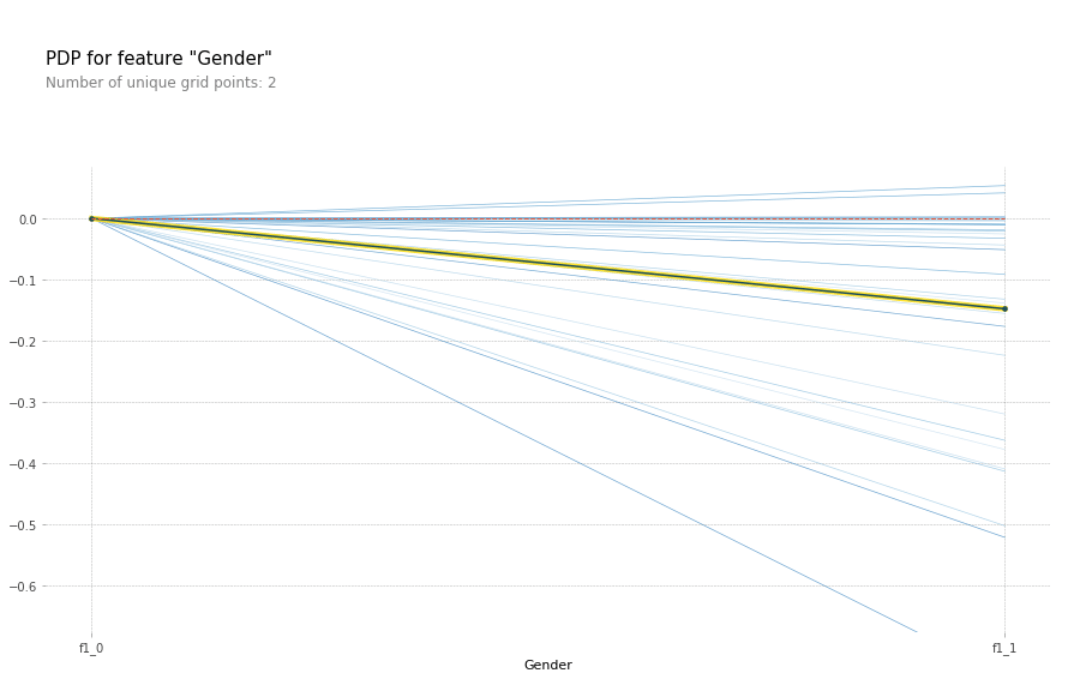
The partial function tells us the average marginal effect for a given value(s) of features S. It gets a PDP estimate for each unique value in the feature by forcing all data points to have the same feature value (e.g., replacing every value of a gender column with female).
For more information on how partial dependence plots work, check out the partial dependence plot section of Interpretable Machine Learning, A Guide for Making Black Box Models Explainable.
Understand individual predictions
Why did the model make this specific prediction? This question becomes increasingly more important as machine learning models are increasingly used in applications like fraud detection or medical tasks because for these kinds of applications, it is imperative to validate and justify the results produced by a model.
LIME (LOCAL INTERPRETABLE MODEL-AGNOSTIC EXPLANATIONS)
Local surrogate models are interpretable models that are used to explain individual predictions of black box machine learning models — Christoph Molnar
In the paper "Why Should I Trust You?" the authors propose a method called Local interpretable model-agnostic explanations (LIME), where surrogate models are trained to approximate the predictions of the underlying black box model locally instead of globally.
It achieves this by creating a new dataset from permuted data points around a data point of interest and the corresponding predictions of the black-box model. LIME then uses this new dataset to train an interpretable model like a tree or linear model, which then can be used to explain the black box model at this local point.
Shapley Values
The Shapley value is a method for assigning payouts to players depending on their contribution to the total payout. But what does this have to do with Machine Learning?
In the case of machine learning, the "game" is the prediction task for a data point. The "gain" is the prediction minus the average prediction of all instances, and the "players" are the feature values of the data point.
The Shapley value is the average marginal contribution of a feature value across all possible coalitions. It is an excellent way of interpreting an individual prediction because it doesn't only give us the contribution of each feature value, but the scale of these contributions is also correct, which isn't the case for other techniques like LIME.

We will take a closer look at local interpretation methods like LIME and Shapley Values in the third part of this series, where we will learn the theory of these techniques and implement them on a real dataset.
Conclusion
Model Interpretability helps debug your model and make your life as a machine learning engineer easier, but it also helps build trust between humans and the model, which is becoming more important as machine learning is used in an increasing number of industries.
What’s next?
In part 2 of this series, we will take a closer look at feature importance and partial dependence plots by diving into the details of these techniques and applying our knowledge using the eli5 and PDPbox libraries.
Thanks for reading the post. If you have any feedback, recommendations, or ideas about what I should cover next, feel free to send me an EMAIL or contact me on social media.