
With the recently released official Tensorflow 2 support for the Tensorflow Object Detection API, it's now possible to train your own custom object detection models with Tensorflow 2.
In this guide, I walk you through how you can train your own custom object detector with Tensorflow 2. As always, all the code covered in this article is available on my Github, including a notebook that allows you to train an object detection model inside Google Colab.
To train a custom object detection model with the Tensorflow Object Detection API, you need to go through the following steps:
- Install the Tensorflow Object Detection API
- Acquiring data
- Prepare data for the OD API
- Configure training
- Train model
- Export inference graph
- Test model
Note: If you want to use Tensorflow 1 instead, check out my old article.
Installation
You can install the TensorFlow Object Detection API with Python Package Installer (pip) or Docker, an open-source platform for deploying and managing containerized applications. For running the Tensorflow Object Detection API locally, Docker is recommended. If you aren't familiar with Docker though, it might be easier to install it using pip.
First clone the master branch of the Tensorflow Models repository:
git clone https://github.com/tensorflow/models.git
Docker Installation
# From the root of the git repository (inside the models directory)
docker build -f research/object_detection/dockerfiles/tf2/Dockerfile -t od .
docker run -it od
Python Package Installation
cd models/research
# Compile protos.
protoc object_detection/protos/*.proto --python_out=.
# Install TensorFlow Object Detection API.
cp object_detection/packages/tf2/setup.py .
python -m pip install .
Note: The *.proto designating all files does not work protobuf version 3.5 and higher. If you are using version 3.5, you have to go through each file individually. To make this easier, I created a python script that loops through a directory and converts all proto files one at a time.
import os
import sys
args = sys.argv
directory = args[1]
protoc_path = args[2]
for file in os.listdir(directory):
if file.endswith(".proto"):
os.system(protoc_path+" "+directory+"/"+file+" --python_out=.")
python use_protobuf.py <path to directory> <path to protoc file>
To test the installation, run:
python object_detection/builders/model_builder_tf2_test.py
If everything was installed correctly, you should see something like:
...
[ OK ] ModelBuilderTF2Test.test_create_ssd_models_from_config
[ RUN ] ModelBuilderTF2Test.test_invalid_faster_rcnn_batchnorm_update
[ OK ] ModelBuilderTF2Test.test_invalid_faster_rcnn_batchnorm_update
[ RUN ] ModelBuilderTF2Test.test_invalid_first_stage_nms_iou_threshold
[ OK ] ModelBuilderTF2Test.test_invalid_first_stage_nms_iou_threshold
[ RUN ] ModelBuilderTF2Test.test_invalid_model_config_proto
[ OK ] ModelBuilderTF2Test.test_invalid_model_config_proto
[ RUN ] ModelBuilderTF2Test.test_invalid_second_stage_batch_size
[ OK ] ModelBuilderTF2Test.test_invalid_second_stage_batch_size
[ RUN ] ModelBuilderTF2Test.test_session
[ SKIPPED ] ModelBuilderTF2Test.test_session
[ RUN ] ModelBuilderTF2Test.test_unknown_faster_rcnn_feature_extractor
[ OK ] ModelBuilderTF2Test.test_unknown_faster_rcnn_feature_extractor
[ RUN ] ModelBuilderTF2Test.test_unknown_meta_architecture
[ OK ] ModelBuilderTF2Test.test_unknown_meta_architecture
[ RUN ] ModelBuilderTF2Test.test_unknown_ssd_feature_extractor
[ OK ] ModelBuilderTF2Test.test_unknown_ssd_feature_extractor
----------------------------------------------------------------------
Ran 20 tests in 91.767s
OK (skipped=1)
Acquiring data
Before you can get started building your object detector, you need some data. If you already have a labeled data-set, you can skip this section and move directly to preparing your data for the Tensorflow OD API.
Public data-sets
If you're more interested in the process of building and using an object detection model, it's a good idea to make use of an already labeled public data-set.
Some great sites to get public data-sets are:
Collect data
If you want to create your own data-set, you first need to get some pictures. To train a robust model, the pictures should be as diverse as possible. So they should have different backgrounds, varying lighting conditions, and unrelated random objects in them.
You can either take pictures yourself or download pictures from the internet. For my microcontroller detector, I took about 25 pictures of each microcontroller and 25 pictures containing multiple microcontrollers.






After you have all the images, move about 80% to the object_detection/images/train directory and the other 20% to the object_detection/images/test directory. Ensure that the images in both directories have a good variety of classes.
Label data
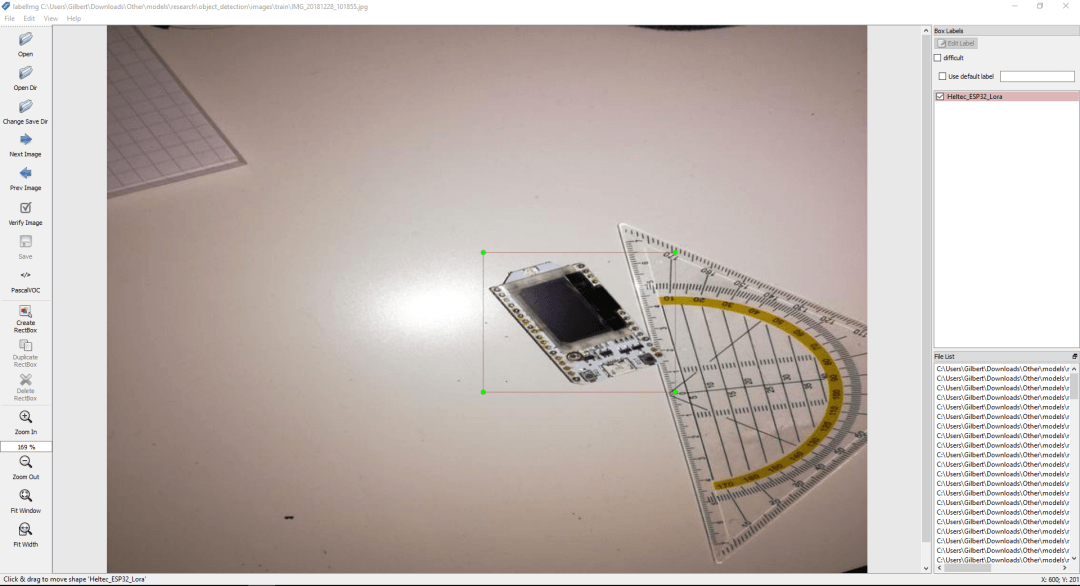
Next, you need to label the images. There are many free, open-source labeling tools that can help you with that.
To get started, I recommend using LabelImg as it can be easily downloaded and used, but there are many other great tools, including VGG Image Annotation Tool and VoTT (Visual Object Tagging Tool).
Prepare data for the OD API
With the data labeled, it's time to convert it to a format the Tensorflow OD API can use. The OD API works with files in the TFRecord format, a simple format for storing a sequence of binary records.
The process of converting your data to the TFRecord format will vary for different label formats. In this article, I'll show you how to work with Pascal VOC format, the format LabelImg produces. You can find files to convert other data formats inside the object_detection/dataset_tools directory.
For the Pascal VOC format, first convert all the XML files into a single CSV file using the xml_to_csv.py file from my Github.
python xml_to_csv.py
Next, download and open the generate_tfrecord.py file and replace the labelmap inside the class_text_to_int method with your own label map.
For my data-set, the class_text_to_int method looks as follows:
def class_text_to_int(row_label):
if row_label == 'Raspberry_Pi_3':
return 1
elif row_label == 'Arduino_Nano':
return 2
elif row_label == 'ESP8266':
return 3
elif row_label == 'Heltec_ESP32_Lora':
return 4
else:
return None
Now the TFRecords can be generated by typing:
python generate_tfrecord.py --csv_input=images/train_labels.csv --image_dir=images/train --output_path=train.record
python generate_tfrecord.py --csv_input=images/test_labels.csv --image_dir=images/test --output_path=test.record
After executing the above commands, you should have a train.record and test.record file inside the object_detection folder.
Configure training
The last thing you need to do before training is to create a label map and a training configuration file.
Labelmap
The label map maps an id to a name. For example, the labelmap for my detector can be seen below.
item {
id: 1
name: 'Raspberry_Pi_3'
}
item {
id: 2
name: 'Arduino_Nano'
}
item {
id: 3
name: 'ESP8266'
}
item {
id: 4
name: 'Heltec_ESP32_Lora'
}
The mapping from id to name should be the same as in the generate_tfrecord.py file.
Training configuration
Next, you need to create a training configuration file based on your model of choice.
In this article, I will use EfficientDet – a recent family of SOTA models discovered with the help of Neural Architecture Search. You can find a list of all available models for Tensorflow 2 in the TensorFlow 2 Object Detection model zoo.
First, download the model from the model zoo:
wget http://download.tensorflow.org/models/object_detection/tf2/20200711/efficientdet_d0_coco17_tpu-32.tar.gz
tar -xf efficientdet_d0_coco17_tpu-32.tar.gz
The base config for the model can be found inside the configs/tf2 folder. It needs to be changed to point to the custom data and pretrained weights. Some training parameters also need to be changed.
The changes look as follows:
- Change the number of classes to the number of objects you want to detect (4 in my case)
- Change
fine_tune_checkpointto the path of the model.ckpt file.
fine_tune_checkpoint: "<path>/efficientdet_d0_coco17_tpu-32/checkpoint/ckpt-0"
- Change
fine_tune_checkpoint_typeto detection - Change input_path of the
train_input_readerto the path of the train.record file:
input_path: "<path>/train.record"
- Change input_path of the
eval_input_readerto the path of the test.record file:
input_path: "<path>/test.record"
- Change label_map_path to the path of the label map:
label_map_path: "<path>/labelmap.pbtxt"
- Change batch_size to a number appropriate for your hardware, like 4, 8, or 16.
Train model
To train the model, execute the following command in the command line:
python model_main_tf2.py \
--pipeline_config_path=training/ssd_efficientdet_d0_512x512_coco17_tpu-8.config \
--model_dir=training \
--alsologtostderr
If everything was setup correctly, the training should begin shortly, and you should see something like the following:
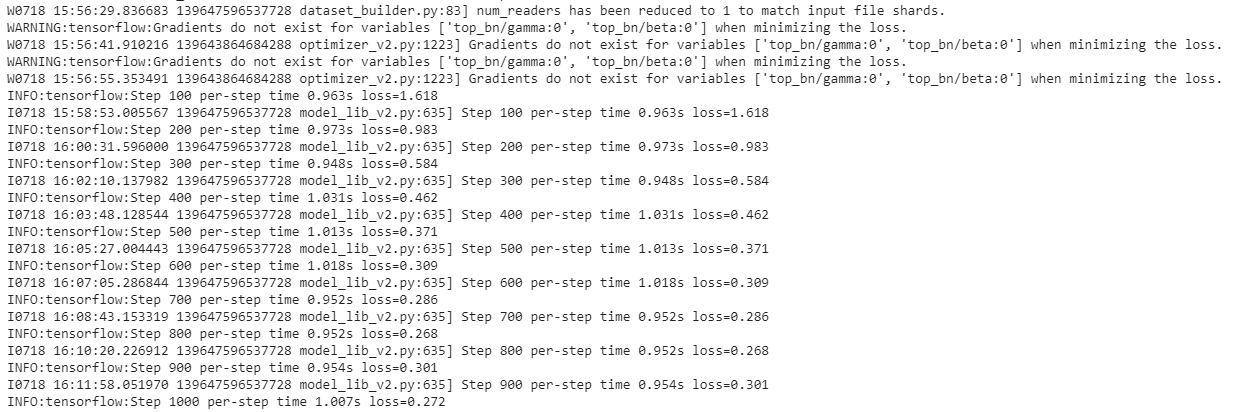
Every few minutes, the current state gets logged to Tensorboard. Open Tensorboard by opening a second command line, navigating to the object_detection folder, and typing:
tensorboard --logdir=training/train
This will open a webpage at localhost:6006.
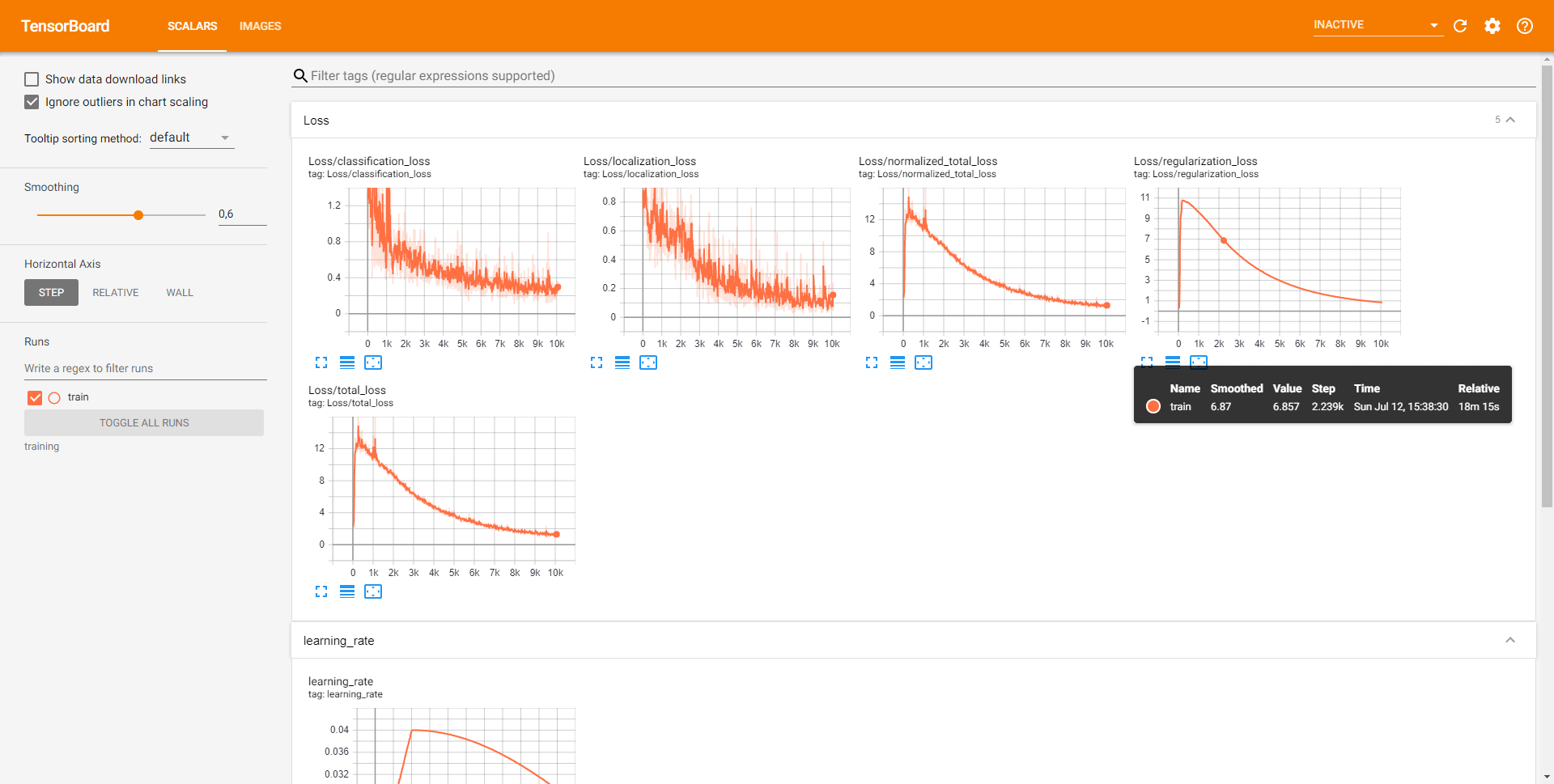
The training script saves checkpoints every few minutes. Train the model until it reaches a satisfying loss, then you can terminate the training process by pressing Ctrl+C.
Export inference graph
To make it easier to use and deploy your model, I recommend converting it to a frozen graph file. This can be done using the exporter_main_v2.py script.
python exporter_main_v2.py \
--trained_checkpoint_dir=training \
--pipeline_config_path=training/ssd_efficientdet_d0_512x512_coco17_tpu-8.config \
--output_directory inference_graph
Test model
Now that you have trained your model and exported it to an inference graph, you can use it for inference. You can find an inference example at the end of the training notebook.







If you want to run the model on a video stream, check out my previous article.