D2Go - Use Detectron2 on mobile devices

D2Go is a production-ready software system from FacebookResearch, which supports end-to-end model training and deployment for mobile platforms.
D2Go
D2Go is a production-ready software system from FacebookResearch, which supports end-to-end model training and deployment for mobile platforms. D2Go provides both built-in command-line tools and an API. This README will walk you through how you can use both the CLI and API to:
- Training a custom model
- Exporting a model to Torchscript
- Quantization-aware Training
Installation
Install PyTorch Nightly (use CUDA 10.2 as an example, see details at PyTorch Website):
conda install pytorch torchvision cudatoolkit=10.2 -c pytorch-nightly
Install Detectron2 (other installation options at Detectron2):
python -m pip install 'git+https://github.com/facebookresearch/detectron2.git'
Install mobile_cv:
python -m pip install 'git+https://github.com/facebookresearch/mobile-vision.git'
Install d2go:
git clone https://github.com/facebookresearch/d2go
cd d2go & python -m pip install .
For more information, check out the installation section of the D2Go README.
Command-line
Inference with a pre-trained model
To run inference with a pre-trained model, navigate into the demo directory, choose a model from model_zoo, e.g. faster_rcnn_fbnetv3a_C4.yaml, and then run the demo.py script.
usage: demo.py [-h] [--config-file FILE] [--webcam] [--video-input VIDEO_INPUT] [--input INPUT [INPUT ...]] [--output OUTPUT] [--confidence-threshold CONFIDENCE_THRESHOLD] [--opts ...]
Detectron2 demo for builtin configs
optional arguments:
-h, --help show this help message and exit
--config-file FILE path to config file
--webcam Take inputs from webcam.
--video-input VIDEO_INPUT
Path to video file.
--input INPUT [INPUT ...]
A list of space separated input images; or a single glob pattern such as 'directory/*.jpg'
--output OUTPUT A file or directory to save output visualizations. If not given, will show output in an OpenCV window.
--confidence-threshold CONFIDENCE_THRESHOLD
Minimum score for instance predictions to be shown
--opts ... Modify config options using the command-line 'KEY VALUE' pairs
Example usage:
wget http://images.cocodataset.org/val2017/000000439715.jpg -q -O input.jpg
python demo.py --config-file faster_rcnn_fbnetv3a_C4.yaml --input input.jpg --output output.jpg

Training a custom model
The CLI also supports training and evaluating custom models, but as far as I know, it only supports the built-in data-sets, including:
- COCO
- LVIS Instance Segmentation
- Cityscapes
- ...
Before training, you need to set up the built-in data-sets. For more information, please follow the instructions on the 'Use Builtin Datasets' page.
To train a model run:
d2go.train_net --config-file ./configs/faster_rcnn_fbnetv3a_C4.yaml
To evaluate a model checkpoint run:
d2go.train_net --config-file ./configs/faster_rcnn_fbnetv3a_C4.yaml --eval-only \
MODEL.WEIGHTS <path to weights>
Note: If you want to train on your custom data-set, I highly recommend using the API instead of the CLI.
Exporting to Torchscript & Int8 Model
You can export a trained model to Torchscript using the d2go.exporter.
Example usage:
d2go.exporter --config-file configs/faster_rcnn_fbnetv3a_C4.yaml \
--predictor-types torchscript --output-dir ./ \
MODEL.WEIGHTS https://mobile-cv.s3-us-west-2.amazonaws.com/d2go/models/246823121/model_0479999.pth
The exporter also supports post-training quantization:
d2go.exporter --config-file configs/faster_rcnn_fbnetv3a_C4.yaml \
--output-dir ./ --predictor-type torchscript_int8 \
MODEL.WEIGHTS https://mobile-cv.s3-us-west-2.amazonaws.com/d2go/models/246823121/model_0479999.pth
Quantization-aware Training
To run quantization-aware training, you need to add the QUANTIZATION section to your model configuration.
d2go.train_net --config-file configs/qat_faster_rcnn_fbnetv3a_C4.yaml \
MODEL.WEIGHTS https://mobile-cv.s3-us-west-2.amazonaws.com/d2go/models/246823121/model_0479999.pth
API
D2Go also provides an API, which allows you to use, train and export your models with a syntax very similar to plain Detectron2. As with Detectron2, I recommend using Google Colab for training the model as Google Colab makes it super simple to get setup and start coding.
Inference with a pre-trained model
To use a pre-trained model for inference, load it from the model_zoo using the get method and create a DemoPredictor.
import cv2
from matplotlib import pyplot as plt
from d2go.model_zoo import model_zoo
from d2go.utils.demo_predictor import DemoPredictor
# get model
model = model_zoo.get('faster_rcnn_fbnetv3a_C4.yaml', trained=True)
# get image
!wget http://images.cocodataset.org/val2017/000000439715.jpg -q -O input.jpg
im = cv2.imread("./input.jpg")
# Create predictor
predictor = DemoPredictor(model)
# Make prediction
outputs = predictor(im)
The predictions can be displayed using the Visualizer.
from detectron2.utils.visualizer import Visualizer
from detectron2.data import MetadataCatalog, DatasetCatalog
v = Visualizer(im[:, :, ::-1], MetadataCatalog.get("coco_2017_train"))
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
plt.imshow(out.get_image()[:, :, ::-1])
You can find all the available models on the "D2Go Model Zoo and Baselines" site.
Training a custom model
Training a custom model with D2Go is almost identical to using plain Detectron2. First, we need to register the data-set, following the detectron2 custom dataset tutorial.
For the ballon segmentation data-set this looks as follows:
# download, decompress the data
!wget https://github.com/matterport/Mask_RCNN/releases/download/v2.1/balloon_dataset.zip
!unzip balloon_dataset.zip > /dev/null
# if your dataset is in COCO format, this cell can be replaced by the following three lines:
# from detectron2.data.datasets import register_coco_instances
# register_coco_instances("my_dataset_train", {}, "json_annotation_train.json", "path/to/image/dir")
# register_coco_instances("my_dataset_val", {}, "json_annotation_val.json", "path/to/image/dir")
import os
import json
import numpy as np
from detectron2.structures import BoxMode
def get_balloon_dicts(img_dir):
json_file = os.path.join(img_dir, "via_region_data.json")
with open(json_file) as f:
imgs_anns = json.load(f)
dataset_dicts = []
for idx, v in enumerate(imgs_anns.values()):
record = {}
filename = os.path.join(img_dir, v["filename"])
height, width = cv2.imread(filename).shape[:2]
record["file_name"] = filename
record["image_id"] = idx
record["height"] = height
record["width"] = width
annos = v["regions"]
objs = []
for _, anno in annos.items():
assert not anno["region_attributes"]
anno = anno["shape_attributes"]
px = anno["all_points_x"]
py = anno["all_points_y"]
poly = [(x + 0.5, y + 0.5) for x, y in zip(px, py)]
poly = [p for x in poly for p in x]
obj = {
"bbox": [np.min(px), np.min(py), np.max(px), np.max(py)],
"bbox_mode": BoxMode.XYXY_ABS,
"segmentation": [poly],
"category_id": 0,
}
objs.append(obj)
record["annotations"] = objs
dataset_dicts.append(record)
return dataset_dicts
for d in ["train", "val"]:
DatasetCatalog.register("balloon_" + d, lambda d=d: get_balloon_dicts("balloon/" + d))
MetadataCatalog.get("balloon_" + d).set(thing_classes=["balloon"], evaluator_type="coco")
balloon_metadata = MetadataCatalog.get("balloon_train")
To verify the data loading is correct, let's visualize the annotations of randomly selected samples in the training set:
import random
dataset_dicts = DatasetCatalog.get('balloon_train')
for d in random.sample(dataset_dicts, 3):
img = cv2.imread(d["file_name"])
v = Visualizer(img[:, :, ::-1], metadata=balloon_metadata, scale=0.5)
v = v.draw_dataset_dict(d)
plt.figure(figsize = (14, 10))
plt.imshow(cv2.cvtColor(v.get_image()[:, :, ::-1], cv2.COLOR_BGR2RGB))
plt.show()

After verifying that the data loaded correctly, we can fine-tune a COCO-pretrained FBNetV3A Mask R-CNN model on the balloon dataset. For this, we need to modify the default faster_rcnn_fbnetv3a_C4.yaml config to work with the balloon data-set.
from d2go.runner import GeneralizedRCNNRunner
def prepare_for_launch():
runner = GeneralizedRCNNRunner()
cfg = runner.get_default_cfg()
cfg.merge_from_file(model_zoo.get_config_file("faster_rcnn_fbnetv3a_C4.yaml"))
cfg.MODEL_EMA.ENABLED = False
cfg.DATASETS.TRAIN = ("balloon_train",)
cfg.DATASETS.TEST = ("balloon_val",)
cfg.DATALOADER.NUM_WORKERS = 2
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("faster_rcnn_fbnetv3a_C4.yaml") # Let training initialize from model zoo
cfg.SOLVER.IMS_PER_BATCH = 2
cfg.SOLVER.BASE_LR = 0.00025 # pick a good LR
cfg.SOLVER.MAX_ITER = 600 # 600 iterations seems good enough for this toy dataset; you will need to train longer for a practical dataset
cfg.SOLVER.STEPS = [] # do not decay learning rate
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 128 # faster, and good enough for this toy dataset (default: 512)
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 1 # only has one class (ballon). (see https://detectron2.readthedocs.io/tutorials/datasets.html#update-the-config-for-new-datasets)
# NOTE: this config means the number of classes, but a few popular unofficial tutorials incorrect uses num_classes+1 here.
os.makedirs(cfg.OUTPUT_DIR, exist_ok=True)
return cfg, runner
cfg, runner = prepare_for_launch()
Now that we have created a config for the ballon data-set, we can create a model and start training.
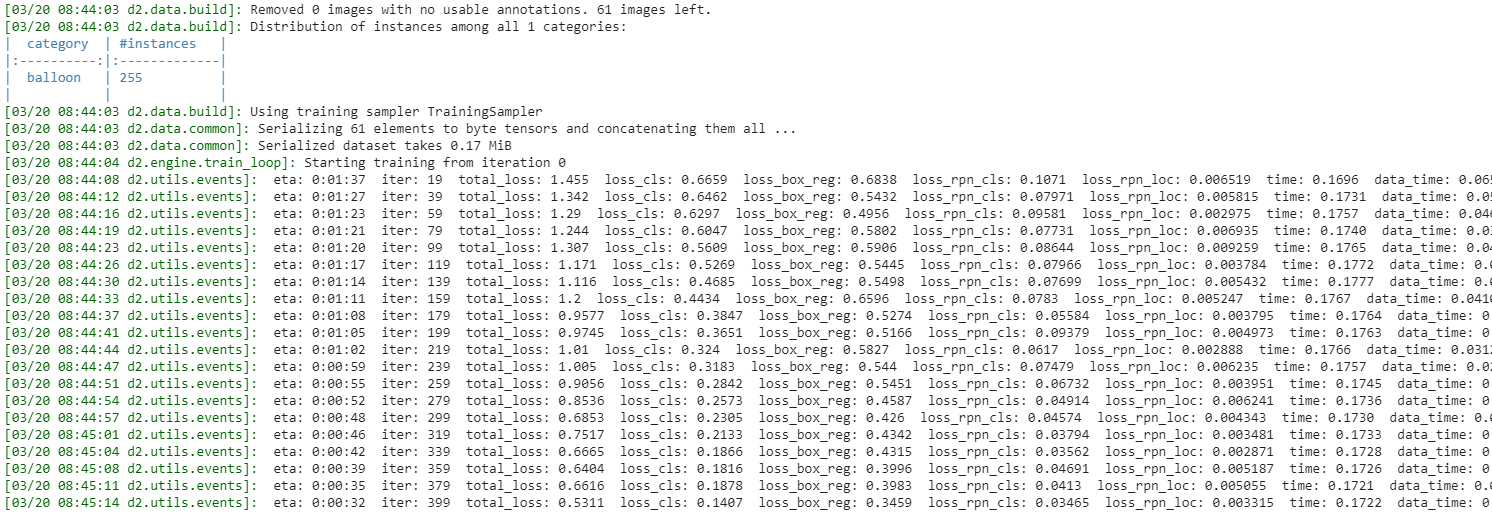
model = runner.build_model(cfg)
runner.do_train(cfg, model, resume=False)
Exporting to Torchscript & Int8 Model
To export the trained model, we need to call the convert_and_export_predictor method, passing it the config, model, and a dataloader.
import copy
from detectron2.data import build_detection_test_loader
from d2go.export.api import convert_and_export_predictor
from d2go.export.d2_meta_arch import patch_d2_meta_arch
import logging
# disable all the warnings
previous_level = logging.root.manager.disable
logging.disable(logging.INFO)
patch_d2_meta_arch()
pytorch_model = runner.build_model(cfg, eval_only=True)
pytorch_model.cpu()
datasets = cfg.DATASETS.TRAIN[0]
data_loader = runner.build_detection_test_loader(cfg, datasets)
predictor_path = convert_and_export_predictor(
copy.deepcopy(cfg),
copy.deepcopy(pytorch_model),
"torchscript_int8@tracing",
'./',
data_loader
)
# recover the logging level
logging.disable(previous_level)
After converting the model, we can test it out by creating a predictor.
from mobile_cv.predictor.api import create_predictor
from d2go.utils.demo_predictor import DemoPredictor
model = create_predictor(predictor_path)
predictor = DemoPredictor(model)
dataset_dicts = DatasetCatalog.get('balloon_val')
for d in random.sample(dataset_dicts, 3):
im = cv2.imread(d["file_name"])
outputs = predictor(im)
v = Visualizer(im[:, :, ::-1], metadata=balloon_metadata, scale=0.8)
v = v.draw_instance_predictions(outputs["instances"].to("cpu"))
plt.figure(figsize = (14, 10))
plt.imshow(cv2.cvtColor(v.get_image()[:, :, ::-1], cv2.COLOR_BGR2RGB))
plt.show()

Deploying model on Android
D2Go can be used on Android using the native torchvision Ops library. The D2Go team provides a D2Go Android demo app that shows how to prepare and use D2Go models on Android. The code is based on a previous PyTorch Android Object Detection demo app that uses a pre-trained YOLOv5 model, with modified pre-processing and post-processing code required by the D2Go model.
Below I'll walk you through the needed steps to get the Android demo work. This is very similar to the README from the demo itself, but it contains a few changes I needed to make to get the demo to work on my machine.
Note: I couldn't get the demo to work on my Windows machine, but it worked on Linux without any problems.
-
Install PyTorch 1.8.0 and torchvision 0.9.0, for example:
conda create -n d2go python=3.8.5 conda activate d2go pip install torch torchvision -
Install Detectron2, mobile_cv, and D2Go
python -m pip install 'git+https://github.com/facebookresearch/detectron2.git' python -m pip install 'git+https://github.com/facebookresearch/mobile-vision.git' git clone https://github.com/facebookresearch/d2go cd d2go & python -m pip install . -
Create the D2Go model
git clone https://github.com/pytorch/android-demo-app cd android-demo-app/D2Go python create_d2go.pyThis will create the quantized D2Go model and save it at
android-demo-app/D2Go/ObjectDetection/app/src/main/assets/d2go.pt.The size of the quantized D2Go model is only 2.6MB.
-
Build and run the D2GO
In Android Studio, openandroid-demo-app/D2Go(notandroid-demo-app/D2Go/ObjectDetection). If an error "Gradle’s dependency may be corrupt" occurs, go to Android Studio - File - Project Structure... , change the Android Gradle Plugin Version to 4.0.1, and the Gradle Version to 4.10.1.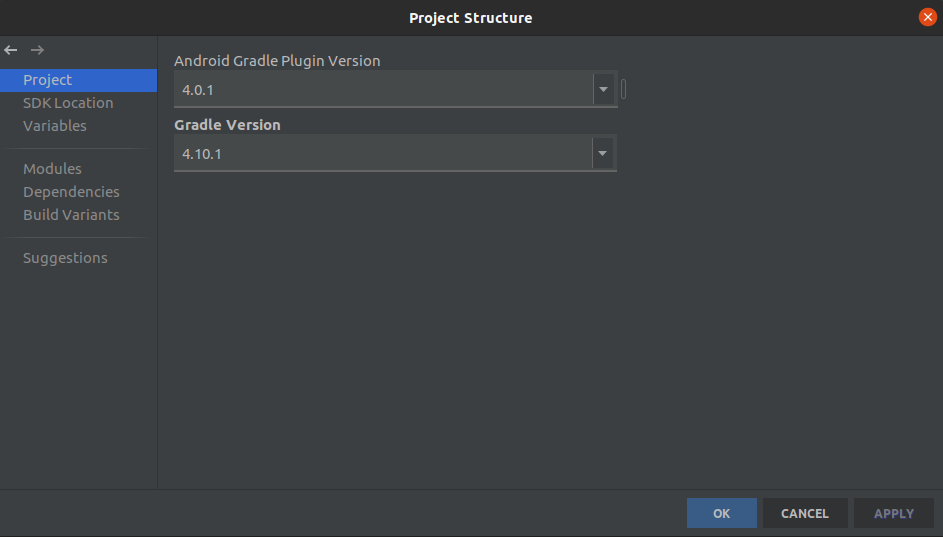
After selecting the correct Gradle version, the project should build without any errors. Once the build is done, you can deploy the model on your Android device or create an Android emulator.
Result:

Deploying a custom model
To use a custom model with the Android demo, the model first needs to br converted, as shown inside the create_d2go.py file.
from typing import List, Dict
import torch
class Wrapper(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.model = model
coco_idx_list = [1]
self.coco_idx = torch.tensor(coco_idx_list)
def forward(self, inputs: List[torch.Tensor]):
x = inputs[0].unsqueeze(0) * 255
scale = 320.0 / min(x.shape[-2], x.shape[-1])
x = torch.nn.functional.interpolate(x, scale_factor=scale, mode="bilinear", align_corners=True, recompute_scale_factor=True)
out = self.model(x[0])
res : Dict[str, torch.Tensor] = {}
res["boxes"] = out[0] / scale
res["labels"] = torch.index_select(self.coco_idx, 0, out[1])
res["scores"] = out[2]
return inputs, [res]
orig_model = torch.jit.load(os.path.join(predictor_path, "model.jit"))
wrapped_model = Wrapper(orig_model)
scripted_model = torch.jit.script(wrapped_model)
scripted_model.save("d2go.pt")
Now that the model was converted and saved as d2go.pt, you need to replace the d2go.pt file inside the android-demo-app/D2Go/ObjectDetection/app/src/main/assets/ folder with your custom model and modify the classes.txt file to contain your custom classes.