
As its name suggests, PRAW is a Python wrapper for the Reddit API, which enables you to scrape data from subreddits, create a bot, and much more.
In this article, we will learn how to use PRAW to scrape posts from different subreddits and get comments from a specific post.
Getting Started
PRAW can be installed using pip or conda:
pip install praw
or
conda install -c conda-forge praw
Now PRAW can be imported by writing:
import praw
Before PRAW can be used to scrape data, we need to authenticate ourselves. For this, we need to create a Reddit instance and provide it with a client_id, client_secret, and user_agent.
reddit = praw.Reddit(client_id='my_client_id', client_secret='my_client_secret', user_agent='my_user_agent')
To get the authentication information, we need to create a Reddit app by navigating to this page, and clicking create app or create another app.
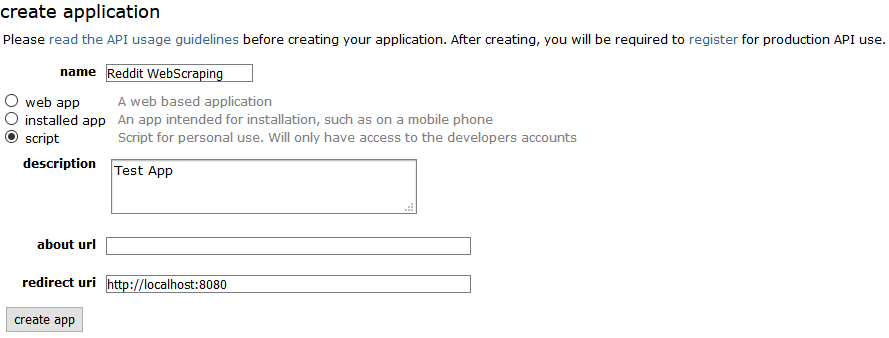
This will open a form where you need to fill in a name, description, and redirect URI. For the redirect URI, you should choose http://localhost:8080 as described in the excellent PRAW documentation.
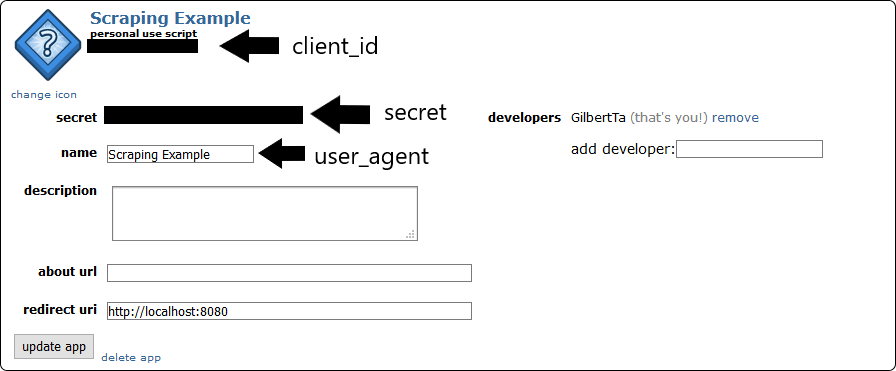
After pressing create app, a new application will appear. Here you can find the authentication information needed to create the praw.Reddit instance.
Get subreddit data
Now that we have a praw.Reddit instance, we can access all available functions and use it to get the 10 "hottest" posts from the Machine Learning subreddit.
# get 10 hot posts from the MachineLearning subreddit
hot_posts = reddit.subreddit('MachineLearning').hot(limit=10)
for post in hot_posts:
print(post.title)
Output:
[D] What is the best ML paper you read in 2018 and why?
[D] Machine Learning - WAYR (What Are You Reading) - Week 53
[R] A Geometric Theory of Higher-Order Automatic Differentiation
UC Berkeley and Berkeley AI Research published all materials of CS 188: Introduction to Artificial Intelligence, Fall 2018
[Research] Accurate, Data-Efficient, Unconstrained Text Recognition with Convolutional Neural Networks
...
We can also get the 10 "hottest" posts of all subreddits combined by specifying "all" as the subreddit name.
# get hottest posts from all subreddits
hot_posts = reddit.subreddit('all').hot(limit=10)
for post in hot_posts:
print(post.title)
Output:
I've been lying to my wife about film plots for years.
I don’t care if this gets downvoted into oblivion! I DID IT REDDIT!!
I’ve had enough of your shit, Karen
Stranger Things 3: Coming July 4th, 2019
...
This variable can be iterated over, and features including the post title, id, and URL can be extracted and saved into a .csv file.
import pandas as pd
posts = []
ml_subreddit = reddit.subreddit('MachineLearning')
for post in ml_subreddit.hot(limit=10):
posts.append([post.title, post.score, post.id, post.subreddit, post.url, post.num_comments, post.selftext, post.created])
posts = pd.DataFrame(posts,columns=['title', 'score', 'id', 'subreddit', 'url', 'num_comments', 'body', 'created'])
print(posts)
General information about the subreddit can be obtained using the .description function on the subreddit object.
# get MachineLearning subreddit data
ml_subreddit = reddit.subreddit('MachineLearning')
print(ml_subreddit.description)
Output:
**[Rules For Posts](https://www.reddit.com/r/MachineLearning/about/rules/)**
--------
+[Research](https://www.reddit.com/r/MachineLearning/search?sort=new&restrict_sr=on&q=flair%3AResearch)
--------
+[Discussion](https://www.reddit.com/r/MachineLearning/search?sort=new&restrict_sr=on&q=flair%3ADiscussion)
--------
+[Project](https://www.reddit.com/r/MachineLearning/search?sort=new&restrict_sr=on&q=flair%3AProject)
--------
+[News](https://www.reddit.com/r/MachineLearning/search?sort=new&restrict_sr=on&q=flair%3ANews)
--------
...
Get comments from a specific post
You can get the comments for a post/submission by creating/obtaining a Submission object and looping through the comments attribute. To get a post/submission, we can either iterate through the submissions of a subreddit or specify a specific submission using reddit.submission and passing it the submission URL or id.
submission = reddit.submission(url="https://www.reddit.com/r/MapPorn/comments/a3p0uq/an_image_of_gps_tracking_of_multiple_wolves_in/")
# or
submission = reddit.submission(id="a3p0uq")
To get the top-level comments, we only need to iterate over submission.comments.
for top_level_comment in submission.comments:
print(top_level_comment.body)
This will work for some submissions, but for others that have more comments, this code will throw an AttributeError saying:
AttributeError: 'MoreComments' object has no attribute 'body'
These MoreComments objects represent the "load more comments" and "continue this thread" links encountered on the websites, as described in more detail in the comment documentation.
There get rid of the MoreComments objects, we can check the data type of each comment before printing the body.
from praw.models import MoreComments
for top_level_comment in submission.comments:
if isinstance(top_level_comment, MoreComments):
continue
print(top_level_comment.body)
But Praw already provides a method called replace_more, which replaces or removes the MoreComments. The method takes an argument called limit, which when set to 0, will remove all MoreComments.
submission.comments.replace_more(limit=0)
for top_level_comment in submission.comments:
print(top_level_comment.body)
Both of the above code blocks successfully iterate over all the top-level comments and print their body. The output can be seen below.
Source: [https://www.facebook.com/VoyageursWolfProject/](https://www.facebook.com/VoyageursWolfProject/)
I thought this was a shit post made in paint before I read the title
Wow, that’s very cool. To think how keen their senses must be to recognize and avoid each other and their territories. Plus, I like to think that there’s one from the white colored clan who just goes way into the other territories because, well, he’s a badass.
That’s really cool. The edges are surprisingly defined.
...
However, the comment section can be arbitrarily deep, and most of the time, we also want to get the comments of the comments. Therefore, CommentForest provides the .list method, which can get all comments inside the comment section.
submission.comments.replace_more(limit=0)
for comment in submission.comments.list():
print(comment.body)
The above code will first output all the top-level comments, followed by the second-level comments, and so on until no comments are left.
Search through comments and submissions with Pushshift
The Reddit API allows you to search through subreddits for specific keywords, but it lacks advanced search features. That's why the /r/datasets mod team designed and created the pushshift.io Reddit API. Pushshift provides enhanced functionality and search capabilities for searching Reddit comments and submissions.
This RESTful API gives full functionality for searching Reddit data and also includes the capability of creating powerful data aggregations. With this API, you can quickly find the data that you are interested in and find fascinating correlations. - Pushshift Readme
To use Pushshift with Python, Github user dmarx created PSAW – the Python Pushshift.io API Wrapper. Using PSAW, you can, for example, search for all posts between the 1st and 3rd of January.
import datetime as dt
from psaw import PushshiftAPI
api = PushshiftAPI()
start_time = int(dt.datetime(2019, 1, 1).timestamp())
end_time = int(dt.datetime(2019, 1, 3).timestamp())
print(list(api.search_submissions(after=start_time, before=end_time subreddit='learnmachinelearning',
filter=['url','author', 'title', 'subreddit'])))
Output:
[submission(author='j_orshman', created_utc=1546464736, subreddit='learnmachinelearning', title='Rapidly Building Reddit Datasets', url='https://www.youtube.com/watch?v=sewtvq5nxM0&t=1s', created=1546457536.0, d_={'author': 'j_orshman', 'created_utc': 1546464736, 'subreddit': 'learnmachinelearning', 'title': 'Rapidly Building Reddit Datasets', 'url': 'https://www.youtube.com/watch?v=sewtvq5nxM0&t=1s', 'created': 1546457536.0}), submission(author='Yuqing7', created_utc=1546460544, subreddit='learnmachinelearning', title='Tsinghua University Publishes Comprehensive Machine Translation Reading List', url='https://medium.com/syncedreview/tsinghua-university-publishes-comprehensive-machine-translation-reading-list-c3f2df594218', created=1546453344.0, d_={'author': 'Yuqing7', 'created_utc': 1546460544, 'subreddit': 'learnmachinelearning', 'title': 'Tsinghua University Publishes Comprehensive Machine Translation Reading List', 'url': 'https://medium.com/syncedreview/tsinghua-university-publishes-comprehensive-machine-translation-reading-list-c3f2df594218', 'created': 1546453344.0}),...]
You can also use pushshift to search and fetch ids and then use PRAW to fetch objects:
import praw
from psaw import PushshiftAPI
r = praw.Reddit(...)
api = PushshiftAPI(r)
Conclusion
Praw is a Python wrapper for the Reddit API, enabling us to use the Reddit API with a clean Python interface. The API can be used for web scraping, creating a bot, and many others.
This article covered authentication, getting posts from a subreddit, and getting comments. To learn more about the API, I suggest looking at their excellent documentation.
The code covered in this article is available as a Github Repository.