
Deep Learning can be used for many interesting things, but it may often feel that only the most intelligent of engineers can create such applications. But this simply isn't true.
Through Keras and other high-level deep learning libraries, everyone can create and use deep learning models no matter his understanding of the theory and inner working of an algorithm.
In this article, we will look at how to use a recurrent neural network to create new text in the style of Sir Arthur Conan Doyle, using his book called "The Adventures of Sherlock Holmes" as our dataset.
We can get the data from the Gutenberg website. We just need to save it as a text (.txt) file and delete the Gutenberg header and footer embedded in the text. If you don't want to do this yourself, you can get the text and all the code covered in this article from my Github.
Recurrent Neural Networks
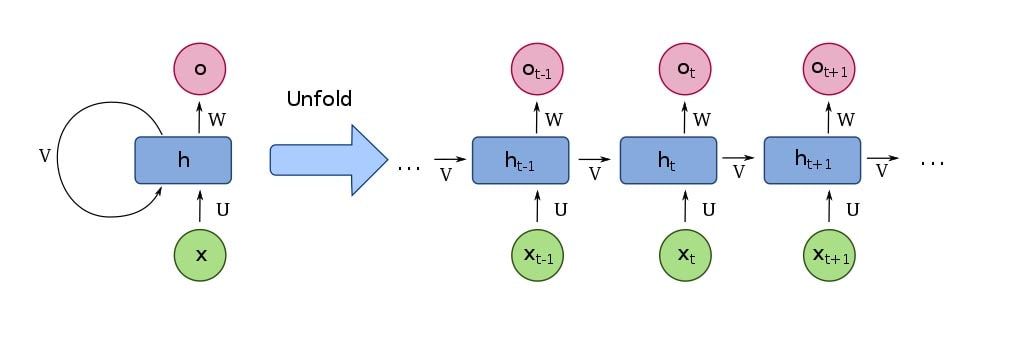
Recurrent Neural Networks(RNN) are the state-of-the-art algorithm for sequential data. This is because they can remember their previous inputs through an internal memory.
In this article, I won't go into how a recurrent neural network works, but if you are interested, you can check out 'Recurrent Neural Networks (RNN) and Long Short-Term Memory (LSTM)' by Brandon Rohrer.
Creating our dataset
As usual, we will start by creating our dataset. To be able to use our textual data with an RNN, we need to transform it into numeric values. We then will create a sequence of characters as our X data and use the following character as our Y value. And lastly, we will transform our data into an array of booleans.
To get started, we will load the data into memory and create a mapping from character to integer and from integer back to character:
with open('sherlock_homes.txt', 'r') as file:
text = file.read().lower()
print('text length', len(text))
chars = sorted(list(set(text))) # getting all unique chars
print('total chars: ', len(chars))
char_indices = dict((c, i) for i, c in enumerate(chars))
indices_char = dict((i, c) for i, c in enumerate(chars))
To get valuable data, which we can use to train our model, we will split our data up into subsequences with a length of 40 characters. Then we will transform the data into a boolean array.
maxlen = 40
step = 3
sentences = []
next_chars = []
for i in range(0, len(text) - maxlen, step):
sentences.append(text[i: i + maxlen])
next_chars.append(text[i + maxlen])
x = np.zeros((len(sentences), maxlen, len(chars)), dtype=bool)
y = np.zeros((len(sentences), len(chars)), dtype=bool)
for i, sentence in enumerate(sentences):
for t, char in enumerate(sentence):
x[i, t, char_indices[char]] = 1
y[i, char_indices[next_chars[i]]] = 1
Recurrent Neural Network Model
Although creating a RNN sounds complex, the implementation is pretty easy using Keras. We will create a simple RNN with the following structure:
- LSTM Layer: will learn the sequence
- Dense(Fully connected) Layer: one output neuron for each unique char
- Softmax Activation: Transforms outputs to probability values
We will use the RMSprop optimizer and the Categorical Crossentropy loss function.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.layers import LSTM
from tensorflow.keras.optimizers import RMSprop
model = Sequential()
model.add(LSTM(128, input_shape=(maxlen, len(chars))))
model.add(Dense(len(chars)))
model.add(Activation('softmax'))
optimizer = RMSprop(learning_rate=0.01)
model.compile(loss='categorical_crossentropy', optimizer=optimizer)
Helper Functions
To see our model's improvements while training, we will create two helper functions. These two functions are from the official LSTM text generation example from the Keras Team.
The first helper function will sample an index from the output(probability array). It has a temperature parameter, which defines the function's freedom when creating text. The second will generate text with four different temperatures at the end of each epoch to see how our model does.
def sample(preds, temperature=1.0):
# helper function to sample an index from a probability array
preds = np.asarray(preds).astype('float64')
preds = np.log(preds) / temperature
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
probas = np.random.multinomial(1, preds, 1)
return np.argmax(probas)
def on_epoch_end(epoch, logs):
# Function invoked at end of each epoch. Prints generated text.
print()
print('----- Generating text after Epoch: %d' % epoch)
start_index = random.randint(0, len(text) - maxlen - 1)
for diversity in [0.2, 0.5, 1.0, 1.2]:
print('----- diversity:', diversity)
generated = ''
sentence = text[start_index: start_index + maxlen]
generated += sentence
print('----- Generating with seed: "' + sentence + '"')
sys.stdout.write(generated)
for i in range(400):
x_pred = np.zeros((1, maxlen, len(chars)))
for t, char in enumerate(sentence):
x_pred[0, t, char_indices[char]] = 1.
preds = model.predict(x_pred, verbose=0)[0]
next_index = sample(preds, diversity)
next_char = indices_char[next_index]
generated += next_char
sentence = sentence[1:] + next_char
sys.stdout.write(next_char)
sys.stdout.flush()
print()
print_callback = LambdaCallback(on_epoch_end=on_epoch_end)
We will also define two other callback functions. The first is called ModelCheckpoint. It will save our model each epoch the loss decreases.
from tensorflow.keras.callbacks import ModelCheckpoint
filepath = "weights.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='loss',
verbose=1, save_best_only=True,
mode='min')
The other callback will reduce the learning rate each time our learning plateaus.
from tensorflow.keras.callbacks import ReduceLROnPlateau
reduce_lr = ReduceLROnPlateau(monitor='loss', factor=0.2,
patience=1, min_lr=0.001)
callbacks = [print_callback, checkpoint, reduce_lr]
Training a model and generating new text
For training, we need to select a batch_size and the number of epochs we want to train. For the batch_size, I choose 128, which is just an arbitrary number. I trained the model for only five epochs, so I didn't need to wait for so long, but if you want, you can train it for a lot more.
model.fit(x, y, batch_size=128, epochs=5, callbacks=callbacks)
Training output:
Epoch 1/5
187271/187271 [==============================] - 225s 1ms/step - loss: 1.9731
----- Generating text after Epoch: 0
----- diversity: 0.2
----- Generating with seed: "lge
on the right side of his top-hat to "
lge
on the right side of his top-hat to he wise as the bore with the stor and string that i was a bile that i was a contion with the man with the hadd and the striet with the striet in the stries in the struttle and the striet with the strange with the man with the struttle with the stratter with the striet with the street with the striet which when she with the strunt of the stright of my stright of the string that i shall had been whi
----- diversity: 0.5
----- Generating with seed: "lge
on the right side of his top-hat to "
lge
on the right side of his top-hat to he had putting the stratce, and that is street in the striet man would not the stepe which we had been of the strude
in our in my step withinst in some with the hudied that in had a had become and the corted to a give with his right with a comon was and confice my could to my sule i was and shugher. i little which a sitter and the site my dippene with a chair drive to be but the some his site with
To generate text ourselves, we will create a function similar to the on_epoch_end function. It will take a random starting index, take out the next 40 chars from the text and then use them to make predictions. As a parameter, we will pass it the length of the text we want to generate and the diversity of the generated text.
def generate_text(length, diversity):
# Get random starting text
start_index = random.randint(0, len(text) - maxlen - 1)
generated = ''
sentence = text[start_index: start_index + maxlen]
generated += sentence
for i in range(length):
x_pred = np.zeros((1, maxlen, len(chars)))
for t, char in enumerate(sentence):
x_pred[0, t, char_indices[char]] = 1.
preds = model.predict(x_pred, verbose=0)[0]
next_index = sample(preds, diversity)
next_char = indices_char[next_index]
generated += next_char
sentence = sentence[1:] + next_char
return generated
Now we can create text by just calling the generate_text function:
print(generate_text(500, 0.2)
Generated text:
of something akin to fear had begun
to be a sount of his door and a man in the man of the compants and the commins of the compants of the street. i could he could he married him to be a man which i had a sound of the compant and a street in the compants of the companion, and the country of the little to come and the companion and looked at the street. i have a man which i shall be a man of the comminstance to a some of the man which i could he said to the house of the commins and the man of street in the country and a sound and the c
Conclusion
Recurrent Neural Networks are a technique for working with sequential data because they can remember the last inputs via an internal memory. They achieve state-of-the-art performance on pretty much every sequential problem and are used by most major companies. For example, an RNN can be used to generate text in a specific author's style.
The steps of creating a text generation RNN are:
- Creating or gathering a dataset
- Building the RNN model
- Creating new text by taking a random sentence as a starting point
The details of this project can be found here. I'd encourage anyone to play around with the code and maybe change the dataset and preprocessing steps and see what happens.
There are also many things you can improve about the model to get better outputs. A few of them are:
- Using a more sophisticated network structure (more LSTM-, Dense Layers)
- Training for more epochs
- Playing around with the batch_size